

在〈認識矩陣〉中談到,如果你的計算過程涉及矩陣運算,想以最後運算出來的矩陣做轉換,可以使用 applyMatrix,那麼來寫個簡單的矩陣程式庫吧!
那麼該怎麼以程式碼來表示矩陣呢?應該直覺地會想到,可以使用 JavaScript 陣列,那麼該怎麼表示呢?以位移矩陣為例:

你會怎麼用陣列表示呢?如下嗎?
[
1, 0, tx,
0, 1, ty,
0, 0, 1
]
視覺上看來,這似乎比較符合矩陣表示法,若你是這麼想,表示你支持列為主(row-major)的派別,在線性陣列中實現時是逐列編寫,也就是這派是這麼看待陣列中的矩陣元素的:
[
row1
row2
row3
]
不過,其實有行為主(column-major)的實現方式:
[
1, 0, 0,
0, 1, 0,
tx, ty, 1
]
也就是在線性陣列中實現時是逐列編寫,也就是這派是這麼看待陣列中的矩陣元素的:
[column1 column2 column3]
那麼 p5.js 中該怎麼做呢?根據 applyMatrix 的 API 文件,若有個矩陣:
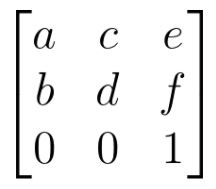
要指定給 applyMatrix 的話,參數順序是 applyMatrix(a, b, c, d, e, f),如果你排版一下:
applyMatrix(
a, b,
c, d,
e, f
);
看來像是以行為主,只不過 0、0 與 1 的部份不用指定;實際上,applyMatrix 可以指定 3D 轉換矩陣,p5.js 也有 3D 版本的轉換函式,以 rotateY API 文件中的這個範例為例:
若要套用轉換矩陣列話,可以如下:
目前還沒有正式介紹 3D 的處理,焦點可以先放在 applyMatrix 接受的參數,其實就是以下轉換矩陣以行為主的表示:
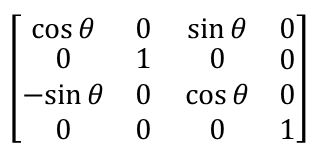
那麼就使用行為主的方式來表達矩陣,來定義出位移、縮放、旋轉與反射等操作:
const mat3 = {
// 移動矩陣
translation(tx, ty) {
return [
1, 0, 0,
0, 1, 0,
tx, ty, 1
];
},
// 縮放矩陣
scaling(sx, sy) {
return [
sx, 0, 0,
0, sy, 0,
0, 0, 1
];
},
// 旋轉矩陣
rotation(degree) {
const c = cos(degree);
const s = sin(degree);
return [
c, s, 0,
-s, c, 0,
0, 0, 1,
];
},
// 反射矩陣(以 (x, y) 向量為鏡)
reflection(x, y) {
const uu = pow(createVector(x, y).mag(), 2);
const xx = x * x;
const yy = y * y;
const xy2 = x * y * 2;
return [
(xx - yy) / uu, xy2 / uu, 0,
xy2 / uu, (yy - xx) / uu, 0,
0, 0, 1,
];
},
// 移動
translate(m, tx, ty) {
return this.multiply(m, this.translation(tx, ty));
},
// 縮放
scale(m, sx, sy) {
return this.multiply(m, this.scaling(sx, sy));
},
// 旋轉
rotate(m, degree) {
return this.multiply(m, this.rotation(degree));
},
// 反射(以 (x, y) 向量為鏡)
reflect(m, x, y) {
return this.multiply(m, this.reflection(x, y));
},
// 轉為 applyMatrix 可用參數
forApplyMatrix(m) {
return m.filter((elem, idx) => (idx + 1) % 3 !== 0);
},
// 矩陣相乘
multiply(a, b) {
const a00 = a[0], a01 = a[1], a02 = a[2];
const a10 = a[3], a11 = a[4], a12 = a[5];
const a20 = a[6], a21 = a[7], a22 = a[8];
const b00 = b[0], b01 = b[1], b02 = b[2];
const b10 = b[3], b11 = b[4], b12 = b[5];
const b20 = b[6], b21 = b[7], b22 = b[8];
return [
b00 * a00 + b01 * a10 + b02 * a20,
b00 * a01 + b01 * a11 + b02 * a21,
b00 * a02 + b01 * a12 + b02 * a22,
b10 * a00 + b11 * a10 + b12 * a20,
b10 * a01 + b11 * a11 + b12 * a21,
b10 * a02 + b11 * a12 + b12 * a22,
b20 * a00 + b21 * a10 + b22 * a20,
b20 * a01 + b21 * a11 + b22 * a21,
b20 * a02 + b21 * a12 + b22 * a22
];
}
};
為了便於 3 x 3 矩陣轉為 applyMatrix 可用的引數,也寫了個 forApplyMatrix,先來看看怎麼使用,對於以下的範例:
可以改寫為以下:
這邊注意一下矩陣計算的順序,如〈認識矩陣〉中談到的,使用 translate、rotate、applyMatrix 等操作時,基本的出發點就是,先畫出圖,再逐一疊加轉換操作,這邊在矩陣運算時,也採取與使用 p5.js 時的 translate、rotate 的順序,結果再餵給 applyMatrix。
來看看這個例子,使用 translate、rotate 來完成不斷繪出變色的圓:
可以觀察到,在角度的變化方面是相同的,若建立可重複使用的引數給 applyMatrix,是否能改變效能呢?
當然,就這個範例來說,可能看不出什麼效能上的差異,這是個概念示範,若有些複雜的座標運算是重複的話,有時可以試著從矩陣運算來思考,看看那些複雜的運算是否可以重用。
另外,在〈座標處理〉中談過,轉換操作會累計,背後都是矩陣運算,其實每個轉換操作呼叫時,都相當於對內部管理的矩陣進行乘法運算,可以用以下程式來模擬一下: